引言
遵循神经缩放定律的计算规模扩展,已极大降低自然语言处理(NLP)和计算机视觉领域的手动特征工程需求,转而通过大规模注意力Transformer模型从数据中自动学习丰富表示[1][2]。这一趋势正深刻变革深度学习推荐系统,这些系统传统上依赖多层感知机(MLP)、图神经网络(GNN)和嵌入表构建架构[3][4][5]。近期,大型序列和生成模型成功部署于在线内容推荐平台,显著提升模型质量[5][7][8][9][10][11][12][13]。鉴于推荐系统的全球规模与重要性[6],将此类大规模序列推荐模型纳入MLPerf Inference基准套件,有助于推动基础设施持续发展。
我们推出DLRMv3,这是MLPerf DLRM系列首个序列推荐推理基准。DLRMv3基于HSTU架构[5]构建排名模型,捕捉现代推荐负载主导计算模式:长输入序列、注意力密集计算和大嵌入表。与现有DLRM基准(DLRMv2 [14])相比,DLRMv3模型规模提升20倍(从50GB至1TB),每候选计算激增6500倍(从40M FLOP至260 GFLOP),仅用三年时间,即与当代生产级推荐负载对齐,凸显计算需求激增。这一高计算体制源于HSTU缩放行为报告,即更高模型计算带来生产质量提升,便于评估真实资源负担与准确率权衡。
任务选择
现代推荐系统通常部署为多阶段管道,将候选检索与排名分离,有时再加重排序或业务逻辑后处理[15][16]。典型设计中,检索模型先从海量语料中选出少量相关项,优化高召回率、覆盖度和严格延迟/内存约束[15][7]。下游排名模型则用更丰富特征和 expressive 架构评分候选,优化细粒度用户互动指标(如点击率CTR、观看时长、满意度),在稍宽松但仍关键的生产延迟/吞吐约束下运行[15][16][18]。这一分阶段设计已成为大规模工业系统标准,包括网页、视频和社会内容推荐。
DLRMv3聚焦管道中的排名阶段。排名模型通常主导生产推荐系统的整体ML计算预算,且是模型架构创新焦点(如注意力序列模型和大嵌入表),特别适合硬件与系统基准测试。聚焦排名也延续了先前MLPerf DLRM基准的CTR预测目标。
形式上,给定用户互动历史(如先前查看/互动项序列)和候选项,DLRMv3模型预测期望结果概率,如点击、点赞或观看。这一概率预测任务直接对齐早期DLRM基准的二元CTR式结果建模。
模型选择
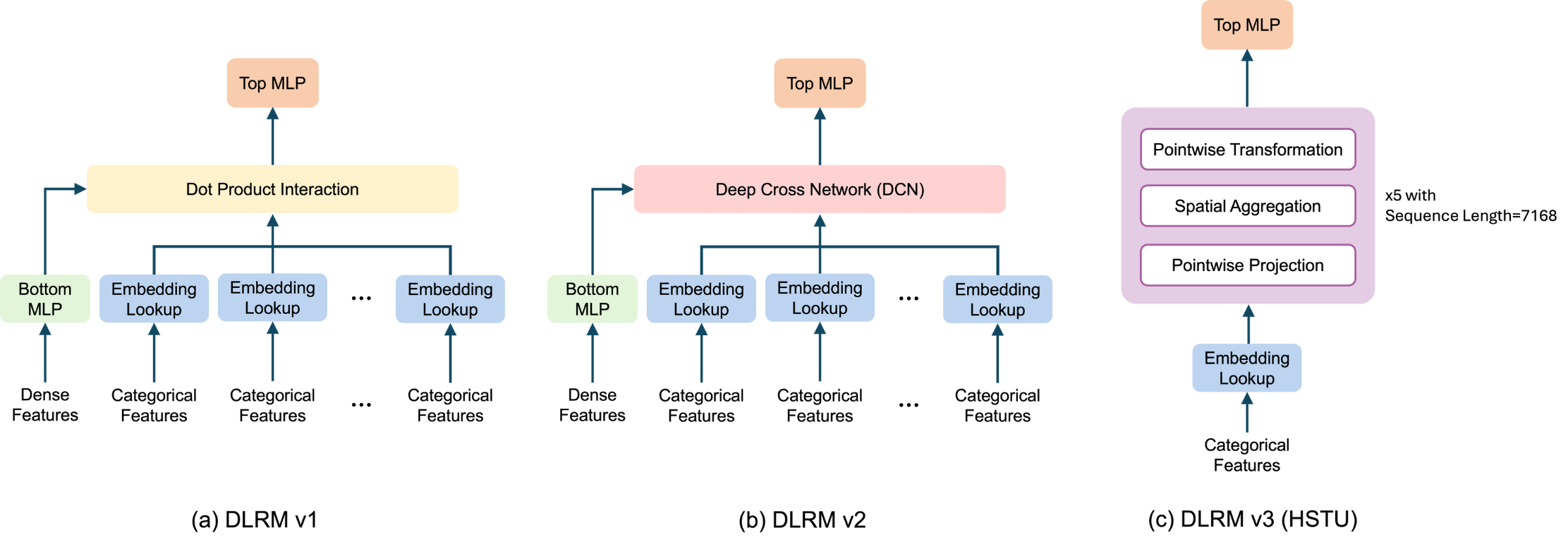
图1. 不同DLRM模型的架构。
我们引入基于HSTU的架构,作为MLPerf第三代深度学习推荐基准(DLRMv3)。在DLRM演进中,DLRMv1由MLP、嵌入表和简单点积特征交互构成,DLRMv2添加深交叉网络(DCN)组件实现更丰富显式特征交叉。DLRMv3引入全新序列特征转换、交互与提取组件,基于分层序列转导单元(HSTU)[5],保留单一大嵌入表和顶层MLP用于最终预测(图1(c))。
HSTU式架构在生产系统中证明,能有效建模长用户互动历史,在相当或更高计算资源下优于传统MLP/DCN模型,提升推荐质量。其计算特征——长序列、注意力密集和大嵌入表——日益主导现代推荐推理,使HSTU成为系统级基准的代表性和前瞻性选择。
下表比较各代DLRM模型配置。260 GFLOP计算公式为2 * layers * (UIH_length * UIH_length * EmbDim / 2 + UIH_length * EmbDim * EmbDim * 4 + UIH_length * EmbDim * EmbDim * 3),涵盖注意力FLOP及前后注意力GEMM。该“每候选”260 GFLOP为有效归一化:典型排名请求中,HSTU编码器仅处理一次共享用户互动历史(UIH)序列,其输出复用于评分候选集(DLRMv3中2K候选),UIH编码主导成本摊销而非重复2K次。此外,DLRMv3采用流式时间序列设置,可复用同一用户连续时间戳的UIH相关KV状态,避免重算UIH编码,在稳态下减少约80–90%冗余稠密计算。
| Model/Input Configurations | DLRMv1 | DLRMv2 | DLRMv3 |
|---|---|---|---|
| Dense Inputs | 13 values | 13 values | 0 values |
| Sparse Inputs per candidate | 26 features, 208 lookups | 26 features, 214 lookups | 1 main feature, ~7K lookups |
| Embedding Tables | 26 tables Total hash size: 200M EmbDim: 128 | 26 tables Total hash size: 200M EmbDim: 128 | 1 main table Hash sizes: 1 billion EmbDim: 512 |
| Feature Interaction | Dot interaction using no trainable parameters | 3 layers of LowRank DCN | 5 HSTU layers, with user interaction history sequence length ~7K |
| Embedding table size (float16 datatype) | ~50GB | ~50GB | 1TB |
| FLOP per candidate | ~5 MFLOP | ~40 MFLOP | ~260 GFLOP |
为更好对齐MLPerf Inference基准目标与实际约束,我们对原HSTU论文设置引入两处有意偏差。这些变更旨在硬件友好、广泛实现,同时捕捉序列推荐模型关键计算模式。
动作嵌入预处理:原HSTU使用上下文交错动作嵌入,将上下文特征与用户动作交织输入序列,提供更丰富上下文学习行为-项依赖。但交错加倍有效序列长度,大增计算成本。DLRMv3基准省略动作交错,改用简化输入序列,直接组合动作嵌入与上下文嵌入不扩展长度。原因:1)合成基准数据集(详见下一节)仅用于性能测量,缺乏足够丰富动作特征支持额外复杂度和双倍长度;2)非交错选项提供更平衡准确率-效率权衡,适合标准化推理基准。
时间/位置编码:原HSTU用相对位置偏差(Mask(SiLU(QKT)+bias)V),捕捉令牌间相对时序关系,提升准确率。DLRMv3改用绝对时间/位置编码,向查询、键、值向量加位置相关偏差,注意力计算为Mask(SiLU(QKT))V。选用绝对偏差因相对偏差引入内核优化挑战、多处理器上减速注意力计算,而绝对编码广泛支持、更易优化、性能更可预测。
数据集选择
不同于DLRMv1/v2,DLRMv3将推荐表述为长用户互动历史的序列转导任务,针对超大项集。为代表现代生产负载,基准数据集需同时满足:(1)每请求合理长用户互动历史(数千事件),充分激活序列模型与注意力层;(2)超大项集,与DLRMv3单一大嵌入表一致(哈希规模约十亿);(3)流式结构,用户查看项与偏好随时间演化,推理请求可按时间重放。